A short journey to long-context models.
Why does it matter?
Training models beyond the 8k context have the following problems:
- the perplexity deteriorates as context length increases
- inability to train with longer context, while keeping the VRAM requirements
- retraining is needed to increase the context size
Attempt to solve this
Tom’s code compatible to transformers library
Loss of Fluency
All LLMs that have been trained so far suffer from a loss of fluency as the input grows too long. When this occurs, the model will lose the ability to produce language, and starts generating e.g. endless newlines, arbitrary characters.

Local LLM runs out of VRAM on subsequent prompts.
Fluency patched
a) LongLoRA has a 2-step process.
Shift short attention:
def shift(qkv, bsz, q_len, group_size, num_heads, head_dim):
qkv[:, num_heads // 2:] = qkv[:, num_heads // 2:].roll(-group_size // 2, dims=2)
qkv = qkv.transpose(1, 2).reshape(bsz * (q_len // group_size), group_size, num_heads, head_dim).transpose(1, 2)
return qkv
Unpacking after attention computations:
output[:, :, self.num_heads//2:] = output[:, :, self.num_heads//2:].roll(group_size//2, dims=1)
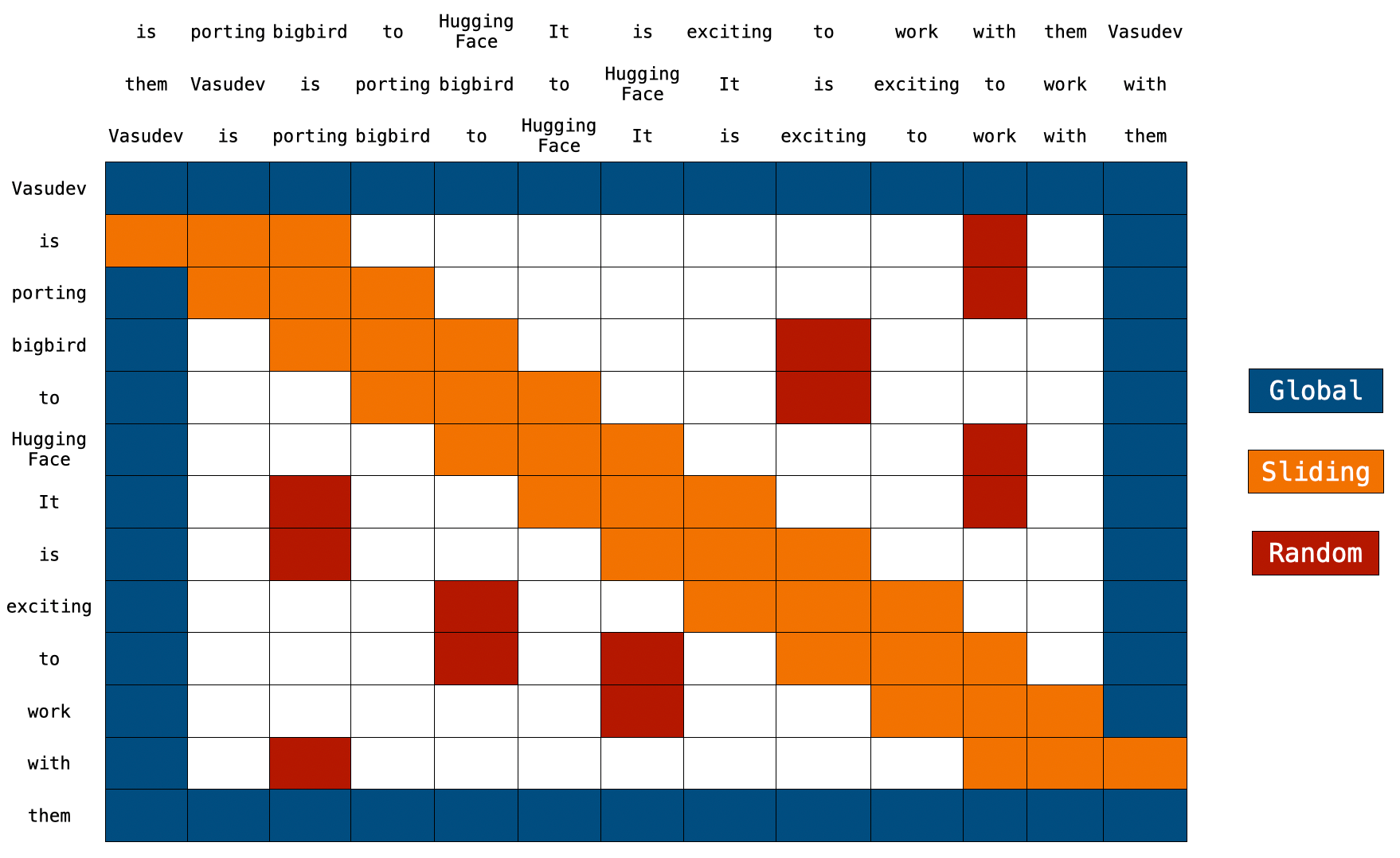
b) Tom’s compatibility layer wraps StreamingLLM implementation, it implements an interface similar to the transformers library.


from attention_sinks import AutoModel
model = AutoModel.from_pretrained(
"meta-llama/Llama-2-7b-chat-hf",
attention_sink_size=4, # These are the yellow blocks
attention_sink_window_size=4092, # These are the blue blocks
)
🟡 attention_sink_size: The number of initial tokens.
🔵 attention_sink_window_size: The size of the sliding window.
Compatible models
GPT-NeoX, Falcon, Mistral, Llama
Is the context window of LLMs expanded?
No. The context window remains unchanged. Only the most recent tokens and attention sinks are retained, discarding middle tokens. This means the model can only process the latest tokens. The context window remains constrained by its initial pre-training.
Can I input an extensive text, like a book, into StreamingLLM for summarization?
While you can input a lengthy text, the model will only recognize the latest tokens. Thus, if a book is an input, StreamingLLM might only summarize the concluding paragraphs, which might not be very insightful.
Longnet handles that case better in my opinion. It does not need as much memory as vanilla attention, but it also does not discard as much information as this implementation. Here is a very good video on how longnet works https://www.youtube.com/watch?v=nC2nU9j9DVQ
Self-attention struggles with long sequences, due to its quadratic dependency on the sequence length. One query would attend to all keys and values, leading to computational inefficiencies. Sparse attention alleviates this issue by restricting the query’s access to a subset of keys and values.
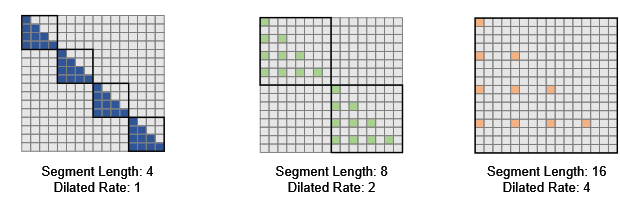
I think this reduces the training time (improve on quadratic time complexity), but the attention is still not spread out unevenly in an infinitely long text - the question that future models need to answer.
So… If this doesn’t actually increase the context window or otherwise increase the amount of text that the LLM is actually able to see/process, then how is it fundamentally different to just “manually” truncating the input to fit in the context size like everyone’s already been doing?
This is a fix for a problem that shouldn’t have been there in the first place. One of the many architectural oversights in the Llama model (and its predecessors).
There isn’t much to see for an end-user. This change won’t mean much to those who use (koboldcpp’s) smart context, summarization or character cards.
Smaller models (7B down to 350M) can handle long conversations better, and they won’t produce garbage output without the truncation of text.
I am still waiting for the breakthrough in large models.
Smaller models (7B down to 350M) can handle long conversations better
What are you basing that on? I mean, it is true there are more small models that support very long context lengths than big ones, but it’s not really because smaller models can handle them better, but because training big models takes a lot more resources. So people usually do that kind of fine-tuning on small models since training a 70B to 32K would take a crazy amount of compute and hardware.
If you could afford fine tuning it though, I’m pretty sure the big model has at least the same inherent capabilities. Usually larger models deal with ambiguity and stuff better, so there’s a pretty good chance it would actually do better than the small model assuming everything else was equal.
I meant smaller models profit more from the stable perplexity in a long prompt with the recently released code changes. Because the paper(s) mention that some of these changes do not require further fine-tuning, we can use small models in a text that is longer than their context size.
It’s practically the same. It’s just faster. It rolls the window further along without needing to recompute the whole context again. It just needs to look at the new tokens, as far as I understand. If you truncate it like we used to do, you have to re-calculate the whole context once you change the first sentence.
The end result is the same.