

They are referencing this paper: LMSYS-Chat-1M: A Large-Scale Real-World LLM Conversation Dataset from September 30.
The paper itself provides some insight on how people use LLMs and the distribution of the different use-cases.
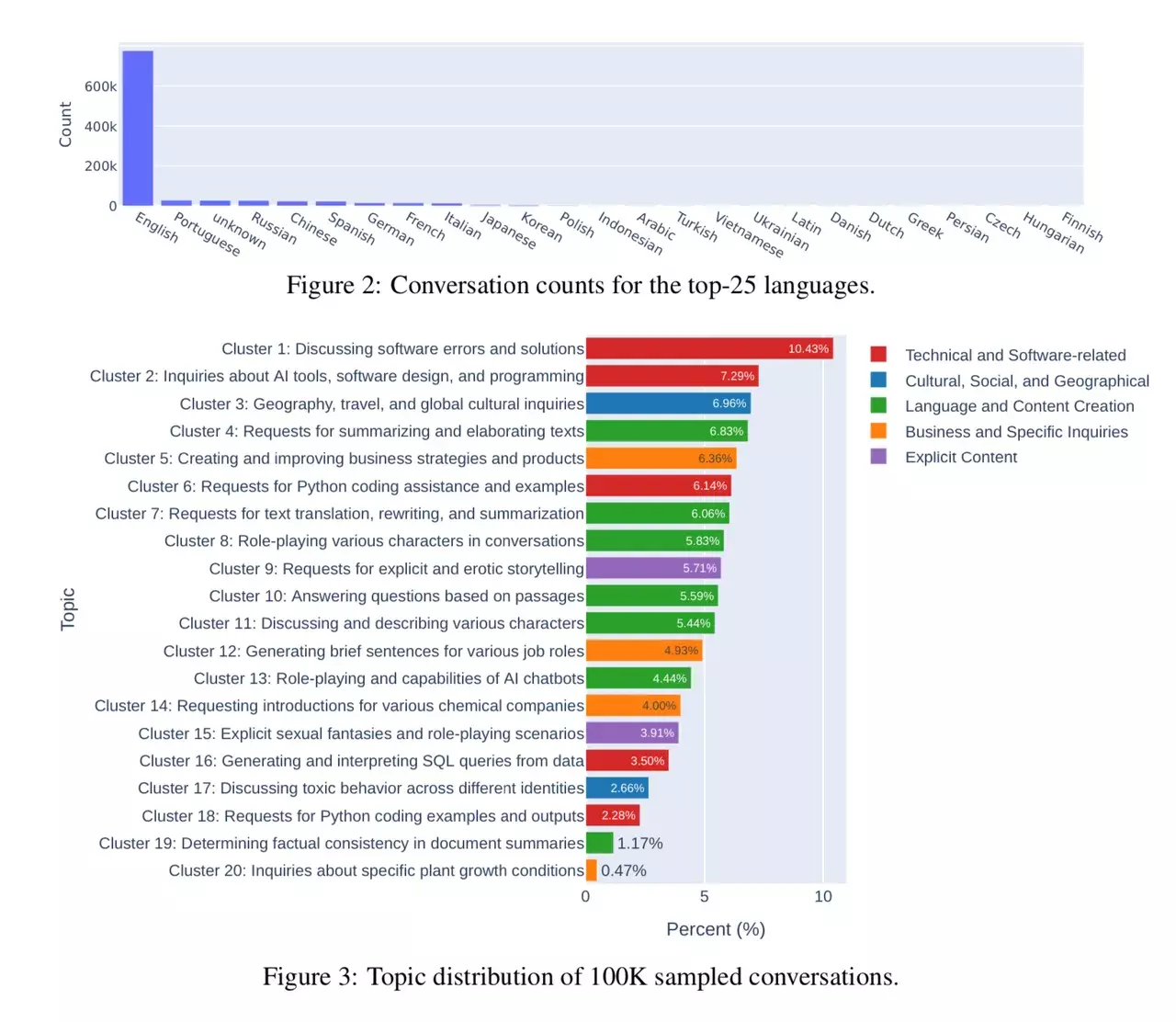
The researchers had a look at conversations with 25 LLMs. Data is collected from 210K unique IP addresses in the wild on their Vicuna demo and Chatbot Arena website.
Stable Diffusion 2 base model is trained using what we would today refer to as a “censored” dataset. Stable Diffusion 1 dataset included NSFW images, the base model doesn’t seem particularly biased towards or away from them and can be further trained in either direction as it has the foundational understanding of what those things are.